布谷鸟过滤器,第一次是在2014年发布的一篇论《Cuckoo Filter: Practically Better Than Bloom》里面提出。
以“布谷鸟”命名,源于该过滤器采用了布谷鸟哈希的思路,而“布谷鸟哈希”算法中的踢出和替换逻辑与布谷鸟的产蛋习性类似。
布谷鸟交配后,雌性布谷鸟就准备产蛋了,但它却不会自己筑巢。它会来到像知更鸟、刺嘴莺等那些比它小的鸟类的巢中,移走原来的那窝蛋中的一个,用自己的蛋来取而代之。– 源自 百度百科
布谷鸟过滤器的数据结构
典型的布谷鸟过滤器是一个4字节一组的二维字节数组buckets,设其数组长度为len,如图1所示。
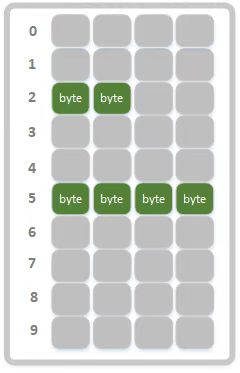
- 数组长度根据预估的待过滤样本量和误差率大小决定,当负载因子到达阈值后可进行扩容以避免误差率的上升。(类似HashMap的扩容方式)
- 每个bucket连续存储4个字节的由key生成的指纹(后续讲解指纹如何计算),之所以使用这种方式存储是为了充分利用cpu缓存机制。这也是布谷鸟过滤器性能优于布隆过滤器的地方,布隆过滤器多个哈希点位内存分布不连续,导致每次读取点位上的数据都需要查询内存,无法充分利用cpu缓存机制。
布谷鸟过滤器的插入
将key插入过滤器的逻辑分以下主要步骤:
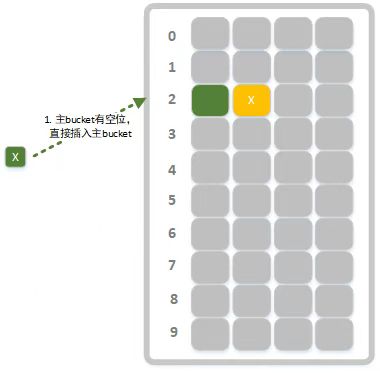
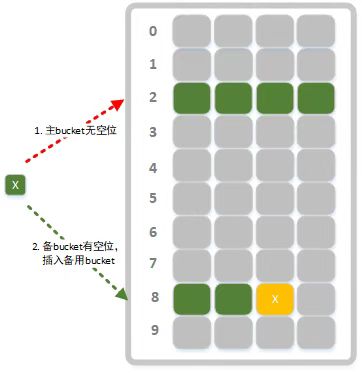
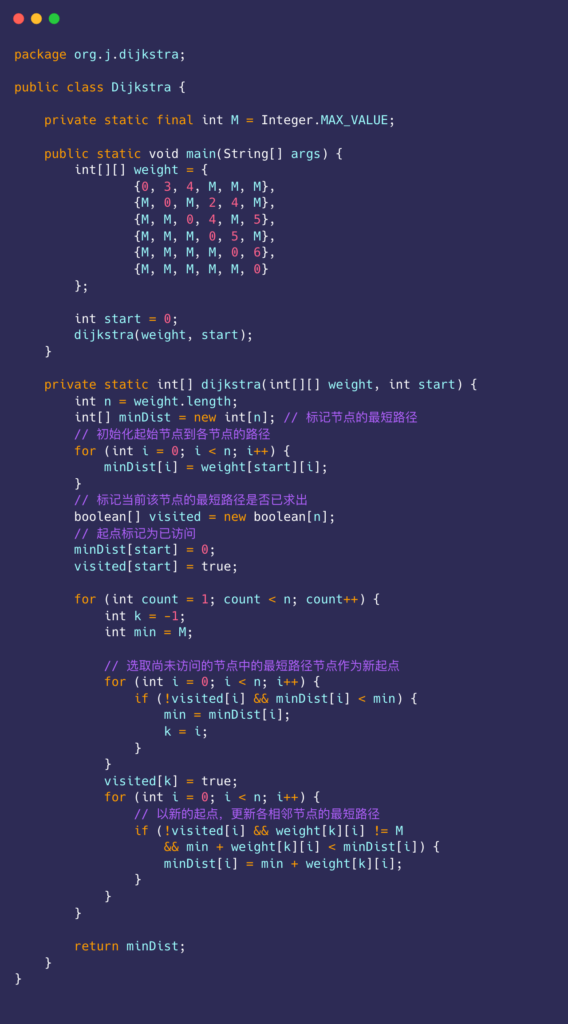
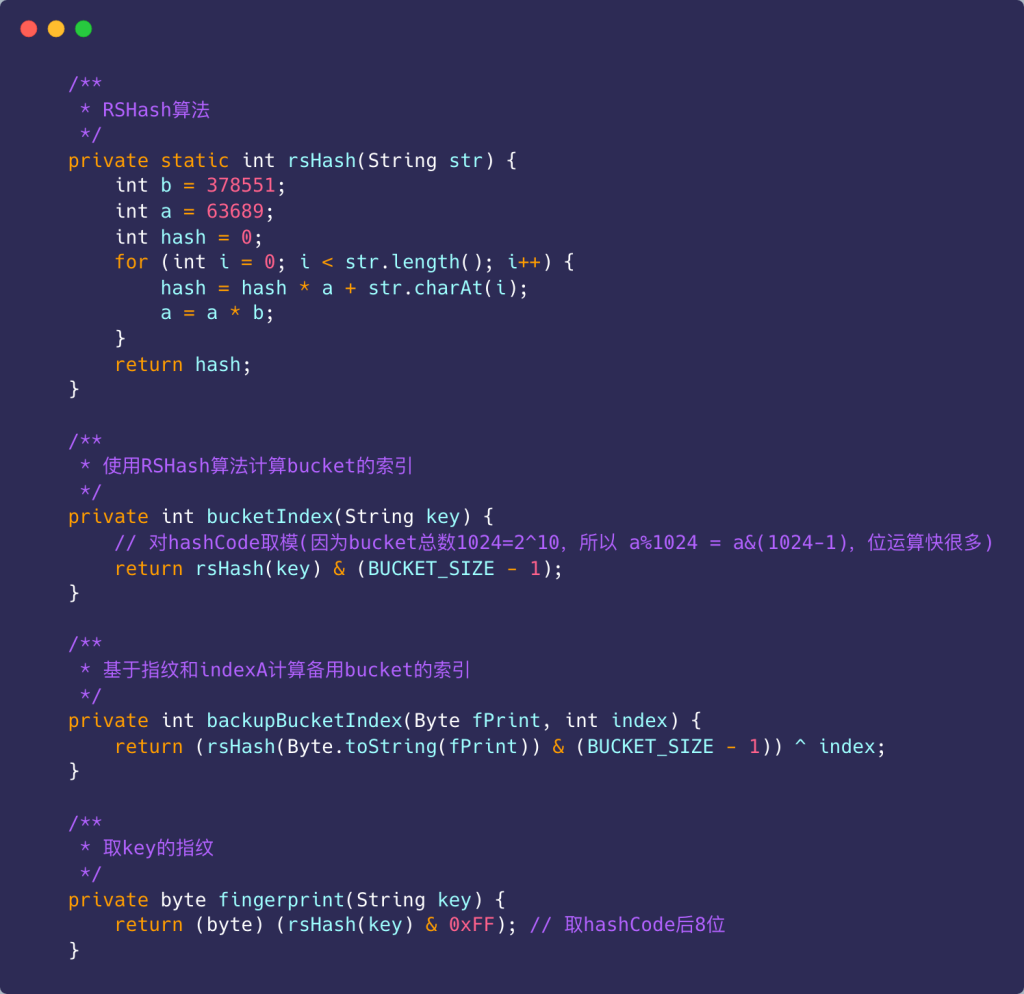
- 用哈希算法rsHash()(本文使用RSHash算法, 也可替换为其他哈希算法)计算key的哈希值hash,结合哈希值和buckets的数组长度可得主bucket在buckets中的索引index = hash % len。
- 使用指纹算法计算出key的指纹fPrint,常用的取指纹算法为步骤1计算所得hash取最后8位,大小为一个字节。取8位仅为在空间占用和判断准确率之间的一种平衡,最高的准确率肯定是将整个hash值作为指纹,但是空间占用也最大,这种平衡也可以根据实际情况调整。
- 遍历bucket尝试找到一个空位插入指纹, 如果插入成功则操作完成(如图2所示)。
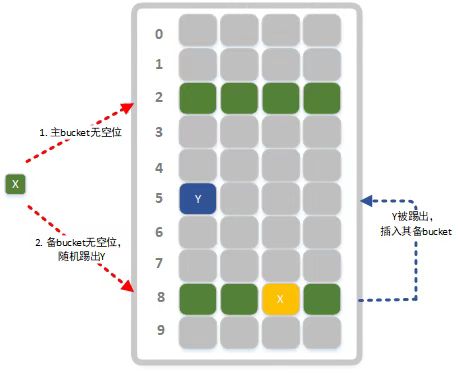
- 如果主bucket无空位则结合指纹fPrint与主bucket索引index计算出备bucket在buckets中的索引backupIndex = index ^ (rsHash(fPrint) % len) (为何使用XOR操作后面会说明)
- 遍历备bucket尝试找到一个空位插入指纹,如果插入成功则操作完成(如图3所示)。
- 如果主备bucket都没有空位插入,则随机踢掉主备bucket8个位置上的某个指纹,插入当前指纹。
- 被踢出的指纹fPrintOut找寻该指纹对应的另一个bucket插入。当另一个bucket也满,则会继续踢出并插入操作,直到找到空位为止(如图4所示)。
而被踢出指纹如何快速找到其对应的另一个bucket,则要用到前面提到的^操作。
由于XOR操作的自反性, a = a ^ b ^ b, 所以
index = index ^ (rsHash(fPrint) % len) ^ (rsHash(fPrint) % len)
= backupIndex ^ (rsHash(fPrint) % len)
主bucket和备bucket可以直接通过XOR操作互相计算得到, 所以当踢出某个指纹时,无需考虑其当前所在的bucket是主bucket还是备bucket,
直接XOR计算就可以得到对应的另一个bucket的索引,效率会非常高。这也是布谷鸟过滤器设计精妙处之一。
布谷鸟过滤器的查询
过滤器的查询就比较简单,参考前面的插入过程。
- 根据key计算指纹和主bucket和备bucket的索引
- 遍历主bucket和备bucket,比对指纹和bucket中所有指纹,如果相等,则判断该key可能存在
- 遍历完如果不存在相等的指纹,则判断该key一定不存在
布谷鸟过滤器的简单Java实现如下:
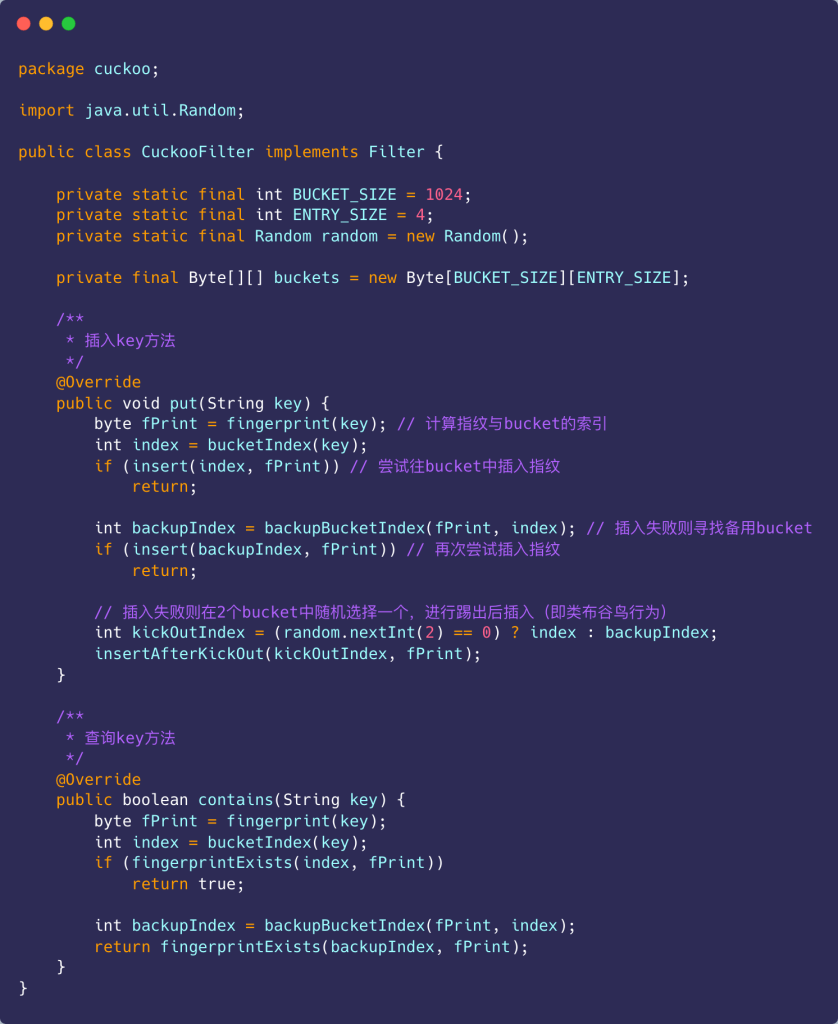
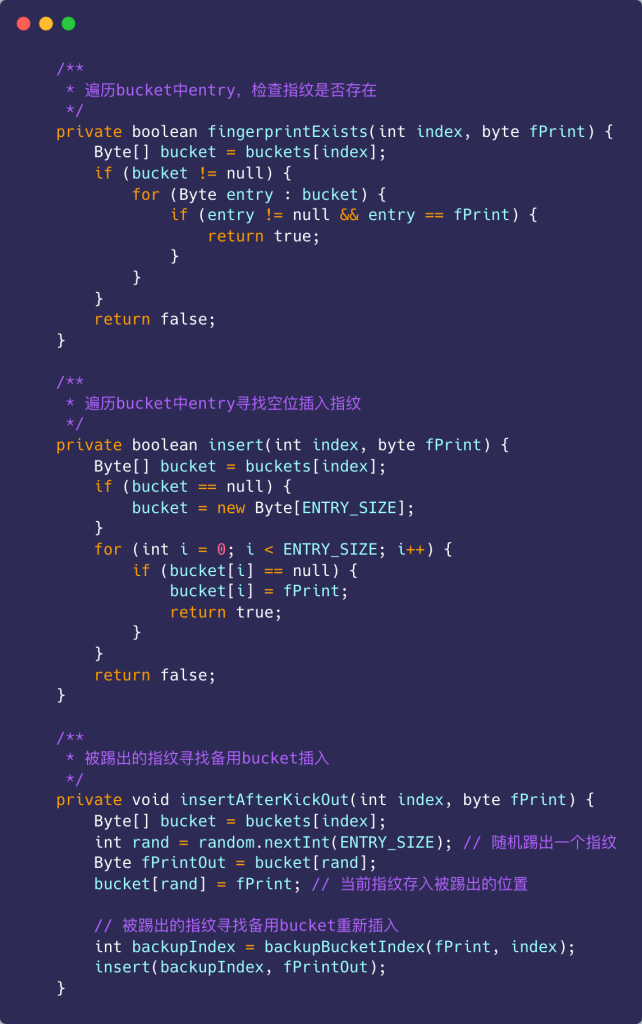
该代码仅实现主要的插入和查询逻辑,待完善部分包含:
- 循环踢出和插入处理逻辑
- 数组达到负载因子后的扩容处理逻辑
- 根据误差率和样本量选择数组容量处理逻辑
附录:
代码请参考: Github地址
本文参考文章链接:
Go语言实现布谷鸟过滤器